Understanding Transformer Model Process in Simple Terms
Learning the Internal Mechanisms of Transformer Model
2025-4-10
transformerattention mechanismmasking
Problem Description
How to understand the training process of the transformer model?
Problem Analysis
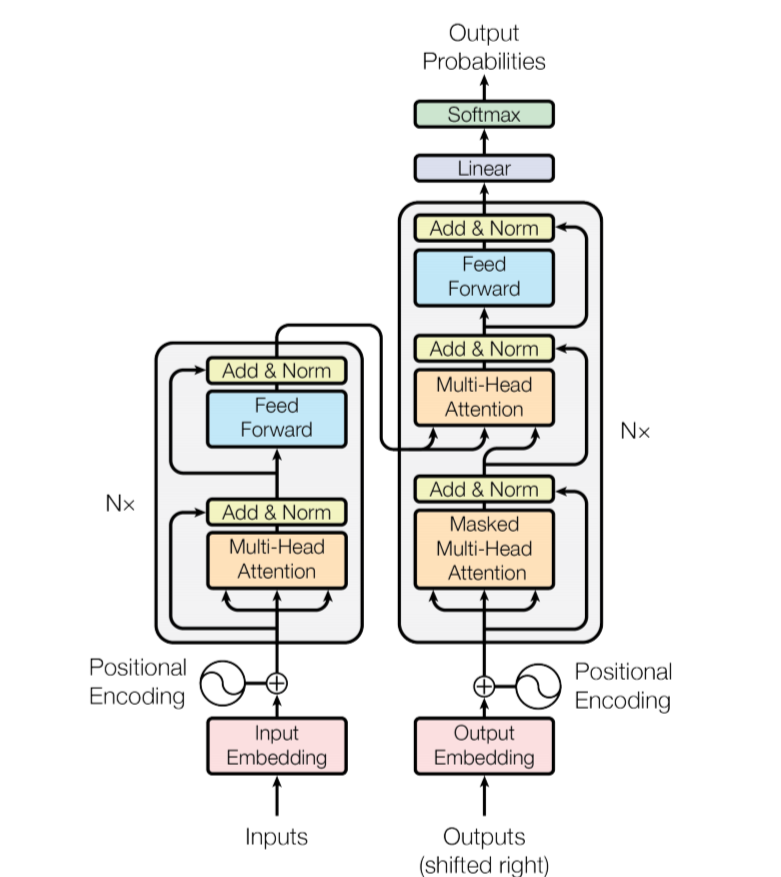
1. Encoder Layer
Let's say our training data is:
const data = [{text:'Cats like to eat fish<eos>'},{text:'Dogs like to eat bones<eos>'}]
- Then use a tokenizer to organize our training data
const trainsData = [
['Cat','like','to','eat','fish','<eos>'],
['Dog','like','to','eat','bones','<eos>']
]
- Obtain contextual relationships between words through calculating attention scores (explaining with a single sample)
Cat's score with Cat is 0, Cat's score with like is 2, Cat's score with eat is 3, Cat's score with fish is 4, and so on
| Cat | like | to | eat | fish | <eos> | |
|---|---|---|---|---|---|---|
| Cat | 0 | 2 | 3 | 4 | 5 | 0 |
| like | 1 | 0 | 5 | 6 | 7 | 0 |
| to | 2 | 3 | 0 | 7 | 8 | 0 |
| eat | 3 | 4 | 5 | 0 | 9 | 0 |
| fish | 4 | 5 | 6 | 7 | 0 | 0 |
<eos> | 4 | 5 | 6 | 7 | 0 | 0 |
- Then we'll get a sample with probabilities, remember our output dimension is still the same as the input dimension
['Cat*0.2','like*0.2','to*0.1','eat*0.3','fish*0.2','<eos>*0.1']
2. Decoder Layer
- The decoding process is similar to the input, but with some changes. The input becomes the following data:
['< SOS >','Cat','like','to','eat','fish']
- Notice that our
<eos>is gone and< SOS >is added at the beginning, this is called a right shift operation - Why do we need to do this? Remember our previous attention scores? We need to do a special operation here:
< SOS > | Cat | like | to | eat | fish | |
|---|---|---|---|---|---|---|
< SOS > | 0 | -inf | -inf | -inf | -inf | -inf |
| Cat | 0 | 0 | -inf | -inf | -inf | -inf |
| like | 0 | 0 | 0 | -inf | -inf | -inf |
| to | 0 | 0 | 0 | 0 | -inf | -inf |
| eat | 0 | 0 | 0 | 0 | 0 | -inf |
| fish | 0 | 0 | 0 | 0 | 0 | 0 |
- -inf represents an extremely small value, meaning no attention score, so
< SOS >cannot see the word Cat, it cannot see the future to calculate loss - We need loss to continuously adjust parameters
sample=['Cat','like','to','eat','fish','<eos>']
label=['< SOS >','Cat','like','to','eat','fish']
3. Final Output
- We have a vocabulary, which is the vocabulary that the tokenizer initially adapted to. Through this vocabulary, we can know which word is being predicted