Transformer模型流程通俗理解
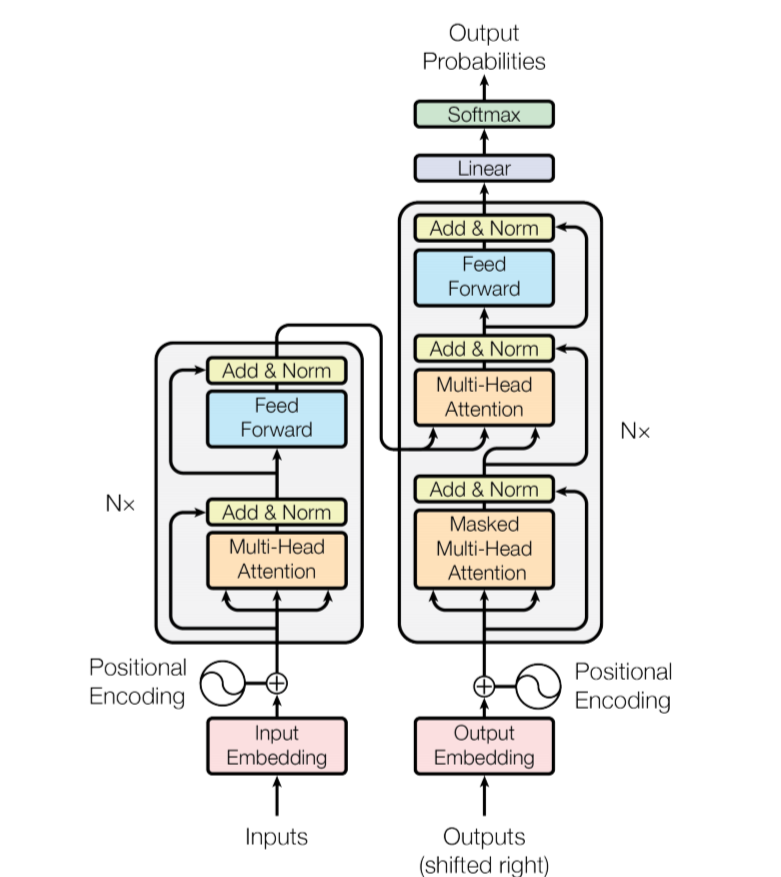
学习Transformer模型内部机制
2025-4-10
transformer注意力机制掩码
问题描述
如何理解transfomer模型训练过程?
问题分析
1. 编码层
假设我们要训练的数据是:
const data = [{text:'猫喜欢吃鱼<eos>'},{text:'狗喜欢吃骨头<eos>'}]
- 再用分词器整理成我们的训练数据
cosnt trainsData = [
['猫','喜欢','吃','鱼','<eos>'],
['狗','喜欢','吃','骨头','<eos>']
]
- 通过计算注意力得分来获取文字之间的上下文关系(单一样本讲解)
猫对猫的得分是0,猫对喜欢的得分是2,猫对吃的得分是3,猫对鱼的得分是4,以此类推
| 猫 | 喜欢 | 吃 | 鱼 | <eos> | |
|---|---|---|---|---|---|
| 猫 | 0 | 2 | 3 | 4 | 0 |
| 喜欢 | 1 | 0 | 5 | 6 | 0 |
| 吃 | 2 | 3 | 0 | 7 | 0 |
| 鱼 | 3 | 4 | 5 | 0 | 0 |
<eos> | 3 | 4 | 5 | 0 | 0 |
- 接着我们会得到一个带有概率的样本,记住我们的输出维度还是跟输入维度是一样的
['猫*0.2','喜欢*0.2','吃*0.3','鱼*0.2','<eos>*0.1']
2. 解码层
- 解码的过程跟输入差不多,只不过有点变化, 输入变成了以下数据:
['<SOS>','猫','喜欢','吃','鱼']
- 看到我们的
<eos>不见了,开头添加了<SOS>,这叫做 右移 操作 - 为什么需要这样做呢,记得我们之前的注意力得分吗,我们要这里做一个神奇操作:
<SOS> | 猫 | 喜欢 | 吃 | 鱼 | |
|---|---|---|---|---|---|
<SOS> | 0 | -inf | -inf | -inf | -inf |
| 猫 | 0 | 0 | -inf | -inf | -inf |
| 喜欢 | 0 | 0 | 0 | -inf | -inf |
| 吃 | 0 | 0 | 0 | 0 | -inf |
| 鱼 | 0 | 0 | 0 | 0 | 0 |
- -inf 就代表极小值,也就是没有注意力的分数,所以
<SOS>不能看到猫这个词,不能看到未来才能求损失 - 有损失才能不断的修正参数
样式=['猫','喜欢','吃','鱼','<eos>']
标签=['<SOS>','猫','喜欢','吃','鱼']
3.最终的输出
- 我们会有个词表,也就是一开始的分词器适应的词表,通过这个词表,我们可以知道预测的是哪个词